第1章 MySQL体系结构与存储引擎
MySQL主要体系结构
- 连接池组件
- 管理服务与工具
- SQL接口组件
- 查询分析器组件
- 优化器组件
- 缓冲(Cache)组件
- 插件式存储引擎
- 物理文件
主要存储引擎介绍
InnoDB
- 支持事务,面向在线事务处理(OLTP)应用。行锁,非锁定读
- 支持外键
- 实现 SQL 四种隔离级别(默认重复读),使用next-key lock 避免幻读
- 数据放在逻辑表空间存储。默认聚集式存储,即每张表都按照主键顺序存放(没有主键会生成 6 字节的 ROWID)
- 其他特性:insert buffer,double write,adapative hash index,read ahead
MyISAM
- 不支持事务。锁级别为表锁
- 索引与文件存放分离
- 缓存只缓存索引
NDB
- 集群设计
- 数据全部位于内存,哈希索引
- (问题)连接操作在MySQL层
Memory
- 数据位于内存,哈希索引
- 表锁降低了并发性
Archive
- 仅支持 INSERT SELECT
- 数据压缩后再存储,比例可达1:10;适合归档数据,日志存放
- 支持行锁,但本身并不事务安全
Maria
- 为了取代原有的MyISAM
- 支持了缓存数据,行锁,MVCC,支持事务
MySQL 连接方式
- TCP/IP套接字:
最通用的连接方式
安全:对于每个用户可以通过权限来分别定制用户允许登入的各个网段,以及各个网段下的不同访问控制权限
- 命名管道/共享内存
在 win 平台,同服务的两个需要通讯的进程可以使用命名管道(通过 –enable-named-pipe)启用。MySQL 4.1以后也可以使用共享内存
- UNIX 域套接字
在 linux 和 UNIX 环境下,同服务的两个进程可以使用。
第2章 InnoDB存储引擎概述
版本
MySQL 5.1 -> InnoDB 1.0 + InnoDB Plugin
MySQL 5.5 -> InnoDB 1.1.x(Linux AIO,多回滚)
MySQL 5.6 -> InnoDB 1.2.x(全文索引,实时索引添加)
体系架构
多个后台线程 + InnoDB引擎内存池 + 文件
后台线程
- Master Thread
核心的后台线程,主要负责将缓冲池中数据异步刷新到磁盘,保证数据一致性(脏页刷新,合并插入缓存,UNDO页的回收)
- IO Thread
InnoDB 大量使用 AIO 处理写 IO 请求。
InnoDB 下的 IO Thread 主要有 write,read,insert buffer,log IO thread 四种。现在版本默认的启用的线程数量为(4write,4read,1insert buffer,1log IO thread)共10个(可以通过 SHOW ENGINE INNODB STATUS查看),读写线程数量都可以分别用 innodb_read_io_threads 和 innodb_write_io_threads 设置
- Purge Thread
负责回收 undo 页
默认在 Master Thread 中完成,1.1 开始可以通过配置启用独立的 Purge Thread(只能为1个)
1.2 开始支持多个 Purge Thread
- Page Cleaner Thread
从1.2 引入,负责 脏页刷新 操作,为了减轻 Master Thread 的工作而引入
内存
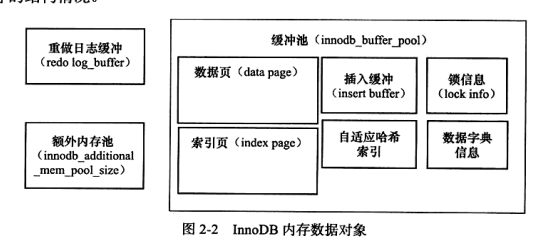
缓冲池
InnoDB 基于磁盘存储,按页管理记录。为了弥补磁盘速度的鸿沟,使用缓冲池技术来提高数据库的整体性能
缓冲池同样以页方式管理,读取时如果数据命中直接使用该页,如果没有则需要去磁盘取。
对于数据库页的修改,首先修改缓存池中的页,然后再以一定的频率刷新到磁盘。刷新回磁盘的发生并不在每次页更新时触发,而是通过一种 checkpoint 机制
缓冲池大小可以通过 innodb_buffer_pool_size 来设置
缓冲池可能包括这些数据页:索引页、数据页、undo页、插入缓冲、自适应哈希索引、数据字典信息,索引和数据页占其中的主要一部分
1.0.x版本开始支持启用多个缓冲池示例,通过innodb_buffer_pool_instances来配置,默认值 1
- LRU list,Free List,Flush List 与 InnoDB 缓冲池管理机制
InnoDB 的缓冲池页通过 LRU 算法管理,不同的是,存在 midpoint insertion strategy 机制,新读取的页不会放到首位,而是先放在 midpoint 位置(原因是避免一些操作引入大量页,但是又只在这一次使用)
这个过程涉及两个参数:innodb_old_blocks_pct innodb_old_blocks_time ,分别代表 新页插入 LRU List 的位置 和 新页经过多少时间才能被加入 LRU 热端
如果 innodb_old_blocks_time 计时结束新页仍存在而使得新页被加入热端,那么这个操作称为 page made young ,否则称为 page not made young,可以通过 SHOW ENGINE INNODB STATUS 查看。
除此之外通过另一个重要参数也可以观察缓冲池的运行效果情况——**Buffer pool hit rate**,通常该值不应该小于 95%,如果低于该值,用户需要观察是否存在全表扫描引起的 LRU 列表污染问题
SHOW ENGINE INNODB STATUS 显示的不是当前状态,而是某个时间范围内的状态。
在输出首部会显示类似 per second seconde averages calculated from the last 60 seconds 的信息,代表下面的数据是过去 60 秒内的数据库状态
- 压缩页
InnoDB 从 1.0.x 开始支持压缩页,可以将原本 16KB 的页压缩为 1KB,2KB,4KB,8KB。非 16KB 的页通过 unzip_LRU 列表管理。
可以在 information_schema 架构通过设置 compressed_size <> 0 条件来查找未压缩的表的情况
- 脏页
LRU 列表中被修改的页称为脏页,会被记载在 Flush 列表中(但是同样存在在 LRU 列表中),会被数据库通过 CHECKPOINT 机制刷新回磁盘
脏页数量也可以通过 SHOW ENGINE INNODB STATUS 查看,形式类似于Modified db pages 32903,代表脏页数量。在 information_schema 架构下没有专门的表显示脏页数量与类型,不过可以通过设置 oldest_modification > 0 条件来进行查询
重做日志缓冲
InnoDB 的重做日志存在两个可能的位置:内存下的重做日志缓冲(redo log buffer)和磁盘上的重做日志文件。不需要太大(保证每秒产生的事务量在这个大小之内),默认 8M
重做日志缓冲会按一定频率冲刷到日志文件,发生刷新的触发情况主要有这三种:
- Master Thread 每一秒将 redo log buffer 冲刷到文件
- 每个事务提交,将 redo log buffer 冲刷到文件
- redo log buffer 的剩余空间小于1/2时,将redo log buffer 冲刷到文件
额外内存池
InnoDB 通过内存堆(heap)管理内存。
在对一些数据结构本身的内存进行分配时,需要从额外的内存池进行申请(缓存池本身的帧缓冲和缓冲控制对象(buffer control block)都需要这些空间
在申请了很大的 InnoDB 缓冲池时,也应考虑增加该值
Checkpoint 技术
checkpoint 技术决定了缓冲池数据和磁盘数据的协调关系
当数据库宕机后,数据库不需要重做所有日志,因为 CheckPoint 之前的页都已经刷新回磁盘
InnoDB 引擎中,Checkpoint 发生的事件、条件和脏页的选择都非常复杂。
在 InnoDB 内部,存在两种 Checkpoint ,分别为:
- Sharp Checkpoint
- Fuzzy Checkpoint
Sharp Checkpoint 发生在数据库关闭时,它会将所有脏页刷新回磁盘,这是默认的工作方式,即参数 innodb_fast_shutdown = 1
当然这种方式不适合运行时使用,所以InnoDB运行中一般使用 Fuzzy Checkpoint 进行页的刷新,即只刷新一部分脏页而不是全部。
InnoDB 中可能发生如下集中情况的 Fuzzy Checkpoint:
- Master Thread Checkpoint:主线程以差不多以每秒或每十秒刷新一定比例脏页回磁盘,异步进行
- FLUSH_LRU_LIST Checkpoint:保证LRU列表至少有一定的空闲页也可供使用,如果没有,会将 LRU 列表尾端页移除,如果移除的页中含有脏页,那么会触发 checkpoint 。这个过程在MySQL 5.6(InnoDB 1.2) 以上会被分给 Page Cleaner 线程检查,不会阻塞用户线程
- Async/Sync Flush Checkpoint:如果重做日志不可用(重做日志记载的LSN 和上次刷新到磁盘的 LSN 差距较大,那么如果再不checkpoint会导致宕机后redo恢复过程太长),当 age 大于 75% 的容量时触发async flush,当 age 大于 90% 时 触发 sync flush。同样,现在被放到了单独的 Page Cleaner 线程,不会阻塞用户线程
- Dirty Page too much Checkpoint:脏页多过一定比例时触发,通过
innodb_max_dirty_page_pct参数设置,比如设为 75 时,当缓冲池脏页超过 75% 时,将触发 checkpoint
Master Thread 工作方式
InnoDB 1.0.x 版本之前的 Master Thread
最高线程优先级
包括多个循环(loop):主循环(loop)、后台循环(backgroup loop)、刷新循环(flush loop)、暂停循环(suspend loop)
主循环
分为每秒操作和每十秒(约)操作:
- 每秒的操作包括:
- 刷新redo日志缓冲到磁盘(即使事务未提交)【总是】;
- (如果IO频率小)合并插入缓冲【可能】;
- (如果大于 dirty_page_pc) 至多刷新 100 个脏页【可能】;
- 没有用户活动则切换到background loop【可能】
- 每10秒操作包括:
- (如果io频率小)刷新100个脏页到磁盘【可能】;
- 合并至多5个插入缓冲【总是】;
- 将日志缓冲刷新到磁盘【总是】;
- 删除无用的Undo页【总是】;
- 刷新100个或者10%脏页到磁盘【总是】。
后台循环和刷新循环
在没有用户活动或者数据库关闭时切换到后台循环
执行这些操作:删除无用的Undo页【总是】;合并20个插入缓冲【总是】;跳回主循环【总是】不断刷新100个页直到符合条件【可能。跳转到 flush loop】
如果在 flush_loop 页没有工作了,那么引擎会切换到 suspend loop,挂起 Master Thread 直到事情的发生
InnoDB 1.2.x 版本之前的 Master Thread
关于【提高主动刷新脏页数和频率】的改进:
innodb_io_capacity 的引入:引入了该参数,可以控制刷新脏页时的行为(默认的100:1. merge Insert buffer 的数量将变为该值的5%;2. 缓冲区刷新脏页时,脏页数量为该值,默认的innodb_io_capacity 值为 200。
innodb_max_dirty_pages_pct**下限默认值降低:该值默认值的90,使得产生 90(90%)的脏页时才刷新 100 个脏页,对于较大内存时对服务器压力较大。该值从1.0.x开始被调节为了 **75
innodb_adaptive_flushing 脏页自适应刷新:使得innodb不再仅当大于 dirty_page_pc 才刷新脏页,而是根据 redo log 自适应调节
innodb_purge_batch_size 可调节回收 Undo 页数量
InnoDB 1.2.x 版本的 Master Thread
主要改动是:1. 根据情况自动选择原本的每10秒操作和每秒操作;2. 分离出一个 Page Cleaner Thread 处理刷新脏页操作
InnoDB关键特性
InnoDB 以下关键特性,的其中三个都是为了合并多次磁盘操作为一次增加磁盘IO效率;另外一个是安全;另外一个是适应性调节
Insert Buffer 插入缓冲
当插入或更新非聚集索引时,将导致原本顺序存放的数据可能变得不再顺序,导致查询非聚集索引时产生离散读写,这可能会影响查找效率
插入操作时,如果对应非聚集索引页不在内存中,不直接插入,而是先放入到 Insert Buffer 对象,期待多个插入能合并到一个索引页
插入缓冲的使用的条件是:索引是辅助索引/索引非唯一,这种情况下InnoDB引擎才会启用 Insert Buffer。
代价是,宕机时内存中可能会有大量 Insert Buffer ,导致恢复时间变长
除此之外,1.0.x 版本之后还引入了 Change Buffer,使得缓冲的适用范围扩展到了所有 DML 操作
这种情况下,一条 update 记录可能分为两个过程:1.将标记标记为删除(change buffer) 2. 真正删除记录(purge buffer)
4.1 版本之后,所有表的InsertBuffer被管理在一个B+树之下
Async IO 异步写
大多数db系统都适用AIO,InnoDB也是如此
好处是可以增加多个IO请求的总体效率,同时还可以Merge多个IO为一个IO
从 InnoDB 1.1.x 开始支持内核级别 AIO (Native AIO),但是需要操作系统支持(Linux,Windows都可以,Mac OSX系统则未提供)
InnoDB中,read ahead方式读取,脏页的刷新都是通过 AIO 完成
Flush Neighbor Page 刷新邻接页
刷新一个脏页时,监测该页所在区(extent)所在的所有页,如果脏页则一起刷新
Apative Hash Index 自适应哈希索引 AHI
生产环境中B+树的高度为34层,需要34次查询,而哈希正常情况的复杂度为O(1)
触发条件:对某个索引页以连续的模式(where a=xxx)访问了100次;页通过该页访问了(页记录*16)次
开启之后,可以通过SHOW ENGINE INNODB STATUS 查看AHI的运行效果,hash searches/s 和 non=hash searches/s 的比例可以反映哈希索引的效率
Double Write 两次写
主要是为了提升数据页可靠性。
仅仅依赖 redo log,如果写页时发生断裂(内存页数据丢失,磁盘页写到一半受损),导致页本身的 checksum 等信息丢失(这个页到底是redolog上的哪个页?!),那么无法通过 redolog 修正。所以需要对写页这一步进行类似缓冲备份的的处理
该机制包含两部分存储:磁盘上(2M*1)和内存(1M*2)中。刷新脏页时,先复制到内存的 doublewrite buffer,然后buffer分两次,每次1MB刷到磁盘上的 doublewrite 段,写满后,再从buffer写入对应idb。
如果断裂发生在doublewrite,那么idb是干净的,可以redo恢复。如果断裂发生在idb,那么通过doublewrite备份覆盖idb,然后再redo恢复
第4章 表
4.2 InnoDB 逻辑存储结构
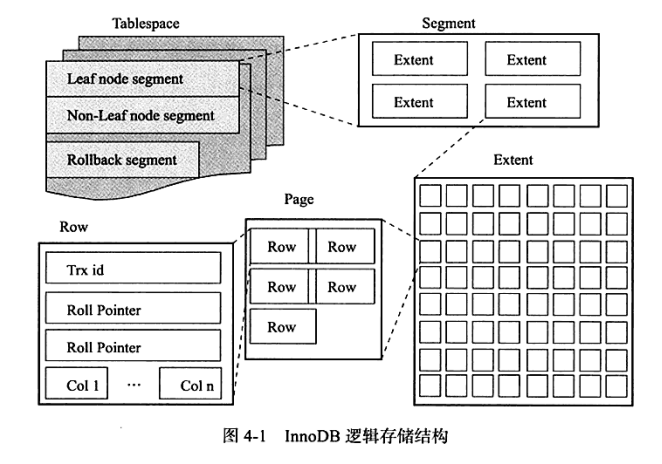
表空间 Tablespace
表空间可以看作 InnoDB 引擎逻辑结构最高层,存放所有数据
默认情况下 InnoDB 有一个共享表空间 ibdata1,所有数据放在该表空间内,如果启用 innodb_file_per_table,则每张表内数据可以单独放到一个表空间内(但是独立表空间仅包含数据,索引,插入缓冲bitmap页)
段 Sagment
表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等
由于之前说过 InnoDB 引擎是索引组织(index organized),数据即索引,索引即数据。也就是说,数据段就是B+树的叶子节点(对应 Leaf node segment),索引段即 B+ 树的非叶子节点(对应 Non-left node segment)。
段的管理由引擎自身完成
区 Extent
区是由连续页组成的空间,任何条件下每个区的大小都是 1MB
为了保证区中页的连续性,InnoDB 存储引擎一次从磁盘申请 4~5 个区
默认情况下一个页的大小为 16KB,则一个区中有 64 个连续页
引入压缩页之后,每个页的大小可以为 2K、4K、8K,此时对应的区包含的页数也会增加
但是对于不满 1MB 的表,每个段会开始时会先用32页大小的碎片页存放数据,用完之后再是对64个连续页的申请
页 Page
页是 InnoDB 磁盘管理的最小单位,默认为 16KB,可压缩
在InnoDB引擎中,常见有这些页类型:
- 数据页
- undo页
- 系统页,数据事务页
- 插入缓冲位图页,插入缓冲空闲列表页
- 未压缩二进制大对象页,压缩的二进制大对象页
行 row
InnoDB 存储引擎是 row-oriented 的,这意味着数据按行存放(面向列)。
4.3 InnoDB 行记录格式
第5章 索引与算法
概述
InnoDB 存储引擎支持以下几种常见索引:B+树索引,全文索引,哈希索引
B+树
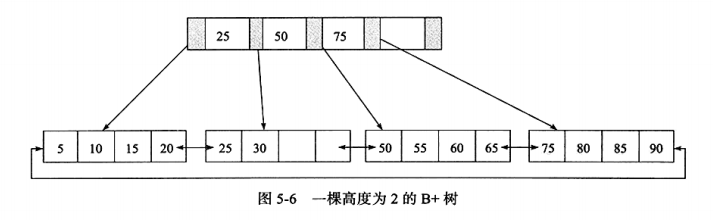
和平衡树类似,当进行插入或者删除时,B+树也可能会发生一些拆分或者旋转等操作。
在数据库中,B+树的高度一般都在24层,查找到某一键值的行记录最多只需要24次IO
聚集索引
InnoDB 存储引擎表是索引组织表,即表中数据按照主键顺序存放。
聚集索引(clustered index)按照每张表的主键构造一棵B+树,叶子节点存放的即为整张表的行记录数据
多数情况下查找优化器会倾向于采用聚集索引。因为聚集索引可以在 B+ 树的索引的叶子节点上直接找到数据。
【如何计算聚集索引高度和存放数据量的关系?】
首先要认识到在一个B+树中,每个【节点】代表一个【页】,而一个节点默认的大小为 16KB 。
对于非叶子节点和叶子节点存放的数据量,存放的内容不同:对于非叶子节点(页),只存放 主键值+页offset 作为指针 ,每条记录(指针)的长度即该两个数据的长度之和,对于bigint(8byte)类型主键,每个记录长度大概在 10几byte 左右,此时每个非叶子节点大概可以存约 1000 条数据,也就 1000 个指针,这 1000 个指针指向了 1000 个页,这也就是说,一层树可容纳的指针数量决定了下一层的节点(页)数,每一层树最多包含的节点数在 1000 个左右,那么3层树可以存储 1000^2 (百万级页)个叶子节点(页),因为每个页为 16KB,粗算来说就是大约 16GB 的数据
然后,对于叶子节点(页),对于聚簇索引页中包含所有数据,每一条记录长度相当于该表每一列(字段)长度之和,所以每一页包含的条数就是 16000Byte / (一行数据字段类型长度和,大约会在几条或者几十条左右,对应上面的结果,3 层数可以达到 几百万到几千万条 数据
因为对于数据库来说,(假设页未命中时)从逻辑页到向物理页取数据的磁盘IO消耗远远大于一个页内查找某条数据,所以说有多少层树就有多少次 IO
如果搜索的树不是非聚簇索引,那么再多一次B+树上的查找消耗
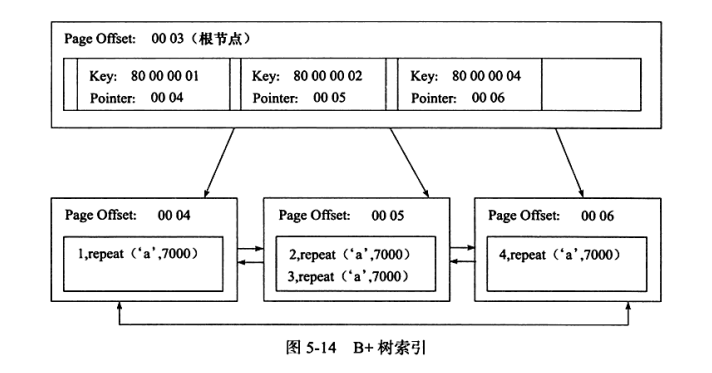
聚集索引的另一个好处是,对于主键的排序查找和范围查找速度非常快
这使得查找 ORDER BY 主键 以及 RANGE BY 主键的操作时,实际过程中不需要额外进行查找(分别表现为Extra 没有显示 using filesort ;type 显示 range)
辅助索引
对于辅助索引,叶子节点不包含行记录全部值,而是 索引键值 + 对应主键值,然后 InnoDB 再拿着这个主键去聚簇索引中寻找内容
B+树索引管理
可以通过 ALTER TABLE 或者 CREATE/DROP INDEX 创建和删除索引
通过 SHOW INDEX 查看一个表的各类索引信息,包括 Cardinality 值等